
Många pratar om AI och data idag. Och många pratar om hälsodata och vilken omvälvning det kommer att bli med AI och hälsodata i hälso- och sjukvården i framtiden.
Här kommer ett perspektiv från mig som spetspatient och civilingenjör.
Jag hoppas att ni kan lära er något av den här texten, oavsett om ni hatar matematik men ägnar er mycket åt egenvård, eller kanske ni är vårdutbildade och jobbar i hälso- och sjukvården. Eller kanske är ni som jag ingenjör som gillar siffror. Ni kommer alla att hitta någonting i den här texten.
Lärande system
AI, Artificiell Intelligens, är system som lär sig och kan lösa olika problem (med olika grad av) självständighet.
Olika användningsområden:
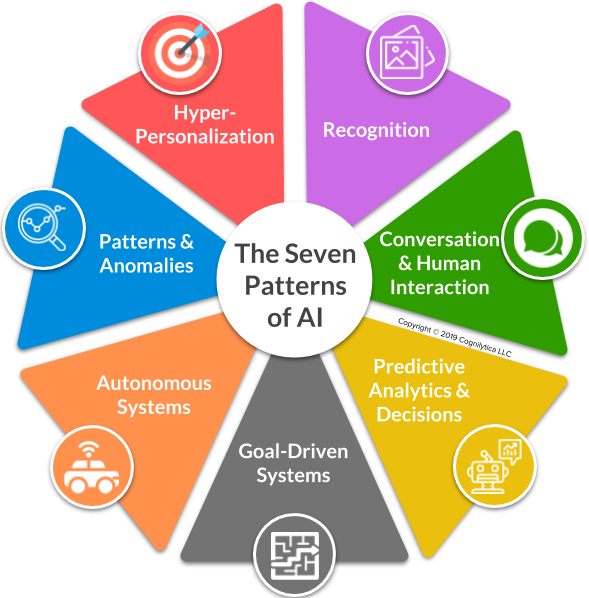
- Hyperpersonalization – Utveckling av en unik profil för varje individ, en profil som eventuellt uppdateras över tiden. Syftet är att behandla varje individ som en individ istället för en medlem i en grupp eller kategoriserad på annat sätt.
- Recognition – Identifiera, bestämma och klassificera objekt eller andra saker från data som kan vara svårt eller tidskrävande att göra för hand.
- Conversational/Human Interaction – Maskiner som interagerar med människor så som människor interagerar med varandra. Tex skriven text, talad text, video och bilder. Innefattar både tolkning av människan men också kunskapen att tex skriva texter som en människa kan läsa och förstå.
- Predictive Analytics & Decision Support – System som med hjälp av inlärda mönster kan förutspå framtida händelser och ev hjälpa människor att ta beslut om exempelvis medicinering.
- Goal-Driven Systems – När ett system har förmågan att lära genom trial and error, dvs testa sig fram. Tex iterative problem lösning, resursoptimering och scenario simulering.
- Autonomous Systems – System som självständigt tar beslut, utför handlingar eller interagerar med omgivningen med ingen är mycket liten mänsklig interaktion.
AI är ett sätt att få maskiner och datorer att dra nytta av tidigare erfarenheter för att generera information och kunskap, precis som människor. Data är olika siffror som beskriver vad som är, har hänt, och kanske kommer att hända. Information är slutsatser man kan dra av det.
Det behöver alltså inte vara så svårt, men när vi blandar in datorer så kan de på ett strukturerat sätt processa betydligt mer data än vi orkar hålla i minnet. Vilket ger ett sätt att lösa andra problem än de vi kan lösa själv. Dock är det långt kvar till generell artificiell intelligens när datorprogram kan lösa helt nya problem eller tolka helt nya omgivningar, detta är något som den mänskliga intelligensen kommer att vara bättre på länge (eller kanske för alltid).
Så vad är data?
Data är… ja, en typ av information, kanske mätvärden, svar på frågor, tankar och minnen, text, ljud mm.
En vanlig indelning för olika nivåer av data är denna:

Om vi behandlar flera olika datapunkter får vi fram information, och från denna information kan vi till slut få fram kunskap, läs mer här. Vad som är data kan skilja sig väldigt mycket, allt från data väldigt nära mätpunkten till data som har bearbetats och processas mycket innan vi kallar det data.
Exempel: Elektriska spänningarna som uppstår i min blodsockermätare är data som behandlas och presenteras som information i form av blodsockervärde. Detta blodsockervärde tolkar jag, och flera olika värden, interventioner och analys ger mig kunskap om hur min kropp fungerar under rådande omständigheter. Exempel: En form av datakälla skulle kunna vara Nationella diabetesregistret, ett kvalitetsregister där man har patienter med diabetes registrerade, därifrån kan vi få reda på hur många som använder insulinpump och vilken blodsockerkontroll de har (mäts med ett labprov som heter HbA1c och är en approximation av medelvärde för blodsockret). Ur det datat kan man dra information kring om det finns ett samband mellan behandlingsmetod och blodsockerkontroll på en gruppnivå. Vilket i sin tur genererar kunskap kring om det är rimligt att förorda någon utav dessa metoder på gruppnivå.
Mätning, uppskattning och att komma ihåg
För att förstå olika typer av data och information kan man dela in det i de tre grupperna, Upplevt, Ihågkommet och Mätbart, se figur.
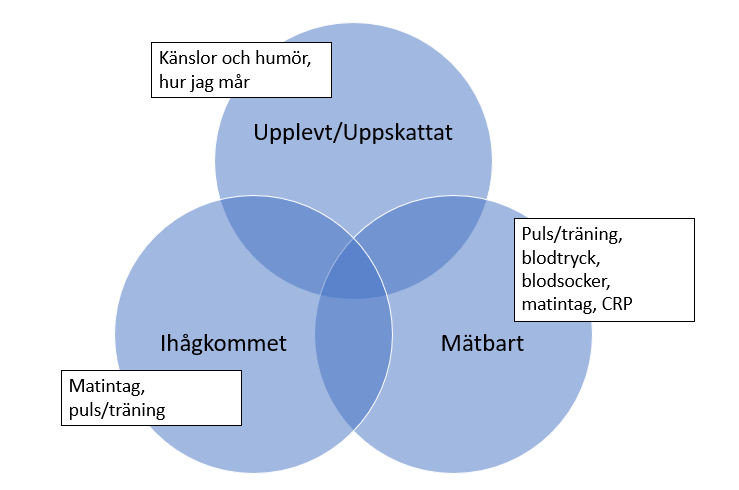
Det här är ju inte helt åtskilda kategorier, vissa saker kan vi både mäta och uppskatta, tex matmängd, medan andra saker är betydligt svårare att mäta, tex känsloreaktioner, och ytterligare datamängder är svåra att uppskatta, tex blodsockervärd.
Skit in – skit ut
Det här är tokigt viktigt för AI, som ligger långt efter människor när det kommer till att avgöra vad som är kasst eller orimligt data eller slutsatser. AI handlar ofta om att bygga upp statistiska modeller och dessa modeller blir inte bra om man blandar data med varierande kvalité.
Balans och mättrötthet
Ju mer desto bättre! Vi mäter och loggar allt så vi kan se så mycket samband som möjligt! Sakta i backarna. Detta är sällan ett bra sätt att resonera. Mätning och loggning tar tid och är avancerat. Vi har för dålig minneskapacitet för att undvika att logga (vi kommer helt enkelt in ihåg vad vi åt till middag förra torsdagen) och vi har inte all tid i världen (vi måste ju leva livet också!). Kontinuerliga mätare tar också tid att administrera, de kliar, sitter i vägen och lossnar när det är som sämst. Det är inte meningsfullt att mäta allt, jämnt. En sådan approach leder till mättrötthet och sämre kvalité på det man mäter.
Data som sprids
Man samlar ju ihop data för att man ska kunna använda den till att dra slutsatser och lära sig nya saker. Ofta vill man samla in för att sedan senare hitta någon som vill analysera datat senare. Då går det inte att i förväg veta hela syftet med insamlingen när man gör den. Det finns snåriga regler kring detta. Men utan att gå in på regelverk så är det viktiga att förstå vad datat säger om oss som individer.
- Helt anonymt data – går inte att spåra till dig som individ. Tex om det är fördelaktigt eller inte med insulinpump jämfört med insulinpenna.
- Avidentifierat data – Tex personen NN som alltid går på bussen vid hållplats Slottskogen går alltid av vid hållplats Domkyrkan. Förutom vissa fredagar, då går NN av vid Centralstationen. Det går att baklänges förstå vem det handlar om, med hjälp av en nyckel som säger NN = Hanna Svensson.
- Identifierbara data – tex Hanna Svenssons sömnmönster är regelbundet.
Mer om detta kan läsas här.
Lästips:
Om lärande system och kontinuerliga förbättringar i egenvård mha PDSA-cykeln: här och här.
You have to know why you are doing this – artikel från BMJ av Sara Riggare, Therese Scott Duncan, Helena Hvitfeldt och Maria Hägglund
Tack för korrekturläsningen Mattias Brännström, Phd, Zenuity; Marcus Österberg, regionutvecklare VGR och Kim Nordlund, Generalsekreterare, Unga reumatikter.